04 Nov 2018
TACO: Learning Task Decomposition via Temporal Alignment for Control
TACO: Learning Task Decomposition via Temporal Alignment for Control
Many advanced Learning from Demonstration (LfD) methods consider the decomposition of complex, real-world tasks into simpler sub-tasks. By reusing the corresponding sub-policies within and between tasks, they provide training data for each policy from different high-level tasks and compose them to perform novel ones. Existing approaches to modular LfD focus either on learning a single high-level task or depend on domain knowledge and temporal segmentation. In contrast, we propose a weakly supervised, domain-agnostic approach based on task sketches, which include only the sequence of sub-tasks performed in each demonstration. Our approach simultaneously aligns the sketches with the observed demonstrations and learns the required sub-policies. This improves generalisation in comparison to separate optimisation procedures. We evaluate the approach on multiple domains, including a simulated 3D robot arm control task using purely image-based observations. The results show that our approach performs commensurately with fully supervised approaches, while requiring significantly less annotation effort.
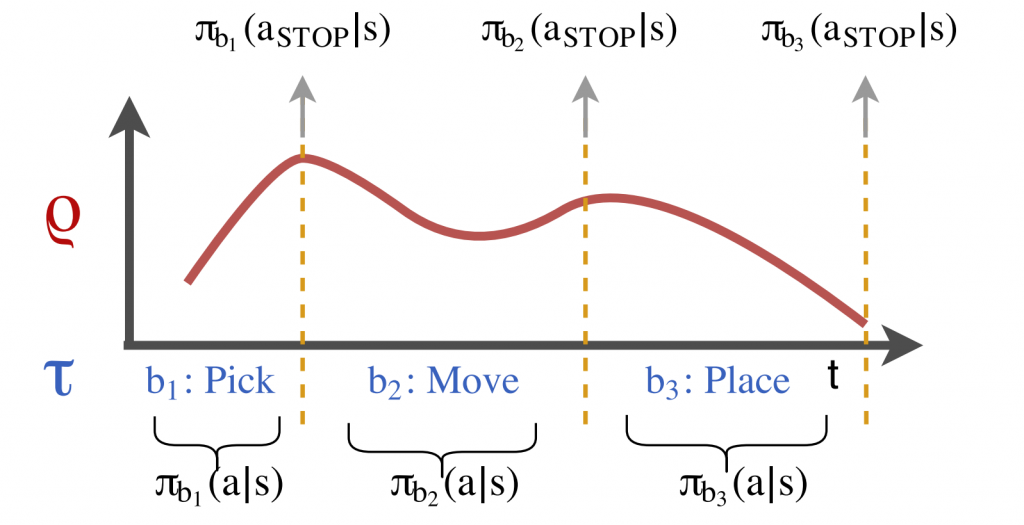
Problem setting: The trajectory ρ (red) is augmented by a task sketch τ (blue). The two sequences operate at different timescales. The whole trajectory is aligned (manually or automatically) and segmented into three parts. From this alignment three separate policies are learned. The unobserved aSTOP action for each policy is inferred to occur at the point where the policies switch from one to the other.
![[PDF]](https://ori.ox.ac.uk/wp-content/plugins/papercite/img/pdf.png) K. Shiarlis, M. Wulfmeier, S. Salter, S. Whiteson, and I. Posner, “TACO: Learning Task Decomposition via Temporal Alignment for Control,” Proceedings of the 35th International Conference on Machine Learning, 2018.
K. Shiarlis, M. Wulfmeier, S. Salter, S. Whiteson, and I. Posner, “TACO: Learning Task Decomposition via Temporal Alignment for Control,” Proceedings of the 35th International Conference on Machine Learning, 2018.



